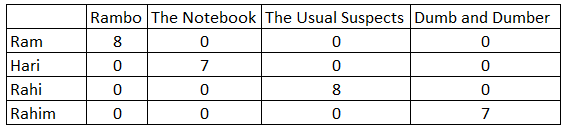
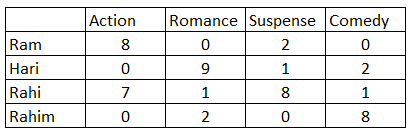
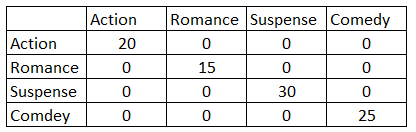
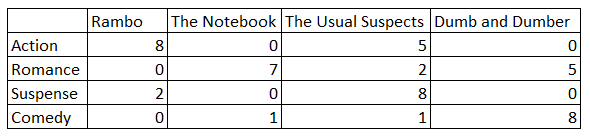
> k=5, model=KNNBasic
-----> Precision: 0.769
-----> Recall: 0.413
> k=5, model=KNNBasic
-----> Precision: 0.773
-----> Recall: 0.416
> k=5, model=KNNBasic
-----> Precision: 0.605
-----> Recall: 0.326
> k=5, model=KNNBasic
-----> Precision: 0.683
-----> Recall: 0.355
> k=5, model=SVD
-----> Precision: 0.754
-----> Recall: 0.386
> k=5, model=SVD
-----> Precision: 0.748
-----> Recall: 0.384
> k=10, model=KNNBasic
-----> Precision: 0.75
-----> Recall: 0.545
> k=10, model=KNNBasic
-----> Precision: 0.752
-----> Recall: 0.559
> k=10, model=KNNBasic
-----> Precision: 0.594
-----> Recall: 0.471
> k=10, model=KNNBasic
-----> Precision: 0.664
-----> Recall: 0.508
> k=10, model=SVD
-----> Precision: 0.739
-----> Recall: 0.522
> k=10, model=SVD
-----> Precision: 0.725
-----> Recall: 0.524